
Avec la montée en puissance des grands modèles de langage comme ChatGPT, de plus en plus d’entreprises commencent à affirmer que leurs modèles sont capables de « raisonner », c’est-à-dire d’extrapoler à partir de leurs connaissances pour produire des conclusions valides, logiquement solides, vis-à-vis d’un tout nouveau problème.
Mais une nouvelle étude repérée par Ars Technica montre de manière flagrante qu’il est encore bien trop tôt pour parler de véritable « raisonnement », et que même les meilleurs modèles actuels ont tendance à s’écrouler de façon spectaculaire lorsqu’on les confronte à des pièges pourtant triviaux.
Un benchmark procédural pour pimenter l’évaluation
Pour le démontrer, les auteurs de cette étude — six ingénieurs d’Apple — se sont appuyés sur GSM8K, un ensemble de données composé de 8000 problèmes mathématiques de niveau école primaire. C’est un benchmark souvent utilisé par les développeurs pour illustrer les soi-disant capacités de « raisonnement » de leurs modèles. Par exemple, la première version de GPT-4 avait atteint un score de 92 % sur ce benchmark, et OpenAI l’a présenté comme une « preuve de ses capacités supérieures de raisonnement mathématique et de résolution de problèmes ».
Le souci, c’est que ce genre de benchmark est assez peu pertinent en pratique. Dans de nombreux cas, les questions et les réponses ont été directement intégrées aux données d’entraînement, et les modèles peuvent donc recracher immédiatement la bonne réponse sans avoir véritablement besoin de raisonner.
Les chercheurs d’Apple ont donc décidé de créer une variante plus rigoureuse de GSMK8, appelée GSM-Symbolic. La grande différence, c’est que ce dernier est un benchmark procédural, dynamique, qui comporte une certaine variabilité. Au lieu de fournir directement les énoncés tels quels aux modèles, l’équipe a créé un programme simple qui permet de remplacer certains éléments par des valeurs différentes. Par exemple, une question sur le temps que prend un pâtissier pour préparer 30 gâteaux peut se transformer en un problème sur un mécanicien qui cherche à réparer 15 voitures.

Ce qui est important, c’est que les chercheurs ont fait très attention à ce que ces modifications n’affectent en rien la nature du raisonnement nécessaire ou la difficulté. Il s’agit exactement du même problème après la modification, simplement maquillé de manière différente. Pour reprendre l’exemple ci-dessus, il faut toujours multiplier le nombre de produits par une unité de temps ; le fait que l’énoncé parle de préparer un dessert ou de réparer un véhicule ne change absolument rien à la façon d’aborder le problème. En théorie, si les LLM étaient véritablement capables de raisonner, ils auraient donc dû obtenir des scores identiques sur GSKM8 et sur GSM-Symbolic, à peu de choses près.
Des pièges logiques triviaux, mais dévastateurs
Mais comme vous vous en doutez probablement, c’est tout l’inverse qui s’est produit ! Les chercheurs ont constaté que l’ensemble des modèles testés, sans exception, a obtenu des scores nettement inférieurs sur GSM-Symbolic. Certains étaient totalement déboussolés par ces changements mineurs. Mistral-7b-it-v0.1, par exemple a vu son score chuter de 9,2 % sur GSM-Symbolic.
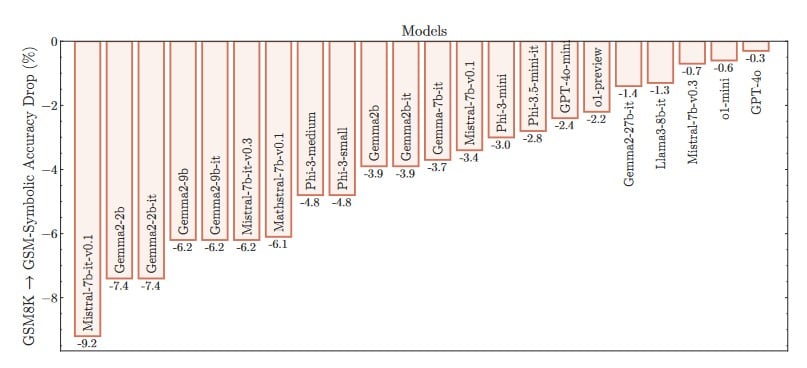
Et ce n’est pas la seule donnée qui illustre de vraies lacunes. Les auteurs ont aussi constaté une très grande variabilité d’un test à l’autre. Sur 50 itérations consécutives de GSM-Symbolic, avec des valeurs différentes à chaque fois mais toujours le même problème de fond, les scores pouvaient varier d’environ 15 % — un chiffre assez énorme dans ce contexte.
En revanche, certains modèles comme GPT-4o s’en sont relativement bien sortis. Le produit d’OpenAI affiche une baisse de 0,3 % d’un benchmark à l’autre, ce qui semble quasiment négligeable à première vue. Peut-on donc considérer qu’il est bel et bien capable de raisonnement logique ?
Pour le vérifier, les chercheurs ont relancé leur expérience en introduisant de nouveaux pièges. Plus spécifiquement, ils ont ajouté des « déclarations apparemment pertinentes mais en fait sans conséquence » aux énoncés. Par exemple, dans une question sur le nombre de kiwis récoltés sur plusieurs jours, les chercheurs ont précisé que certains fruits étaient un petit peu plus petits que les autres. Puisque la réponse ne dépend absolument pas de la taille ou du poids des kiwis, un adulte aurait vite compris qu’il ne faut pas tenir compte de cette précision.
Un jeune enfant serait-il tombé dans le panneau ? Peut-être, et il aurait été intéressant de disposer d’une étude comparative réalisée dans une salle de classe pour en juger. Mais ce qui est certain, c’est que les LLM se sont tous laissés berner. Ces diversions pourtant basiques leur ont complètement fait perdre les pédales, conduisant à ce que les chercheurs décrivent comme des « baisses de performances catastrophiques ». GPT-4o, qui s’en était bien sorti sur le test précédent, a vu son score chuter de 32 %. D’autres se sont complètement écroulés, comme Phi-3-mini-128k-instruct et son affligeant -65,7 % de précision…

Pas de vrai raisonnement chez les LLM
Pour les auteurs de l’étude, ces chiffres pointent vers une « faille critique ». Cela suggère qu’il existe de véritables « problèmes de fond dans le processus de raisonnement » qui ne peuvent pas être résolus simplement en affinant les poids et les biais qui conditionnent le fonctionnement des modèles. Pour faire mieux, il faudrait repartir de zéro avec une architecture totalement différente.
Sur la base de ces résultats très éloquents, les chercheurs avancent que les « LLM actuels ne sont pas capables d’un véritable raisonnement logique ». Ils tâchent en fait de masquer cette lacune en « essayant de répliquer les étapes de raisonnement relatives à d’autres problèmes présents dans leurs données d’entraînement ». En d’autres termes, ils se comportent un peu comme un jeune élève qui aurait appris son livre d’exercices par cœur ; ils peuvent obtenir une excellente note tant qu’ils restent en terrain connu, mais l’illusion s’écroule immédiatement dès qu’on les sort de leur zone de confort, puisqu’ils n’ont finalement rien compris à la logique sous-jacente.
C’est une conclusion qui ne surprendra probablement personne. Après tout, ces LLM sont essentiellement des systèmes prédictifs qui sont très doués pour reconnaître des motifs qui nous échappent. Au bout du compte, ils restent des machines à jouer aux devinettes. Certes, ils le font de manière souvent très efficace, mais cela reste une approche fondamentalement différente d’un véritable raisonnement construit.
C’est loin d’être la première fois que des spécialistes rejettent l’idée que les LLM sont doués de raison, mais cette étude est une belle démonstration de l’immense fossé qui sépare les revendications des entreprises et la réalité concrète. N’en déplaise à Sam Altman, PDG d’OpenAI, l’intelligence artificielle générale (AGI) qu’il mentionne si souvent est encore très loin d’être à la portée des modèles actuels.
Vers un grand changement de paradigme ?
Plus largement, on peut légitimement s’interroger par rapport aux limites des LLM actuels. Cela fait longtemps que des spécialistes affirment que l’approche actuelle finira probablement par se heurter à un mur, notamment à cause d’un processus d’entraînement inapproprié. Les humains en sont un bon exemple.
On sait pertinemment qu’ingurgiter des informations brutes pour en extraire des motifs récurrents, comme le font les LLM ne suffit pas. Si le cursus scolaire des enfants consistait simplement à mémoriser l’ensemble du dictionnaire et des millions de pages de tables d’additions et de multiplications, ils souffriraient probablement des mêmes lacunes logiques que les modèles IA ! S’ils sont capables de construire une vraie intelligence au fil de leur vie, c’est avant tout parce qu’on leur inculque des notions plus abstraites, conceptuelles, sur lesquelles ils peuvent s’appuyer par la suite.
Tout l’enjeu, c’est de trouver une manière de faire de même avec les modèles IA. Mais il s’agit d’un énorme défi technique qui passera sans doute par un grand changement de paradigme à moyen, voire long terme.
Il conviendra donc de suivre les progrès des chercheurs en IA, car cette révolution technologique ne fait que commencer. Mais en parallèle, croisons aussi les doigts pour que les entreprises cessent de pousser ces termes trompeurs, qui peuvent inciter les internautes moins technophiles à penser qu’ils ont déjà affaire à des entités conscientes et véritablement intelligentes.
Le texte de l’étude est disponible ici.
🟣 Pour ne manquer aucune news sur le Journal du Geek, abonnez-vous sur Google Actualités et sur notre WhatsApp. Et si vous nous adorez, on a une newsletter tous les matins.










Alors pourquoi continue-t-on d’investir autant de milliard dedans pour avoir un résultat plus décevant qu’une «embauche» de stagiaires ? Ils espèrent y arriver ou pas ?!
C’est vraiment désopilant de lire tout ces articles sur ce sujet depuis 2 ans, on a l’impression d’un progrès en carton avec des tas de personnes qui craignent que son utilisation les forces à devenir tous prof’ pour machins/machines avant de devoir terminer prompt-engineer en 2 mois.
Et si l’on commençait tout bonnement à leur apprendre La Logique ( mathématique), celle que l’on trouve, par exemple excellent, chez René CORI et Daniel LASCAR dans “Logique mathématique”, en n’oubliant pas ce bon vieux Stephen C. KLEENE (Logique mathématique dans la précieuse édition de Jacques Gabay en 1987) ? L’IA serait alors comme ces étudiants de Diderot que nous fûmes, à la fin par là capables de construire des raisonnements parfaitement valides (au sens de La Logique) ?
Quelque chose m échappe dans tout ça. Bien évidemment les LLM ne raisonnent pas. Je capte pas. Ce qui est interessant avec eux c est de travailler la paire de lunettes qu on leur colle devant leurs yeux pour obtenir le contenu désiré. (Prompt). En quoi un truc qui élabore des discussions en terme de probabilités pourrait il raisonner. ? Et pourquoi se poser la question. Sauf si on a mis des milliards dans un truc qu on croyait facile à aborder ?
Je me permet de retourner la conclusion de l’article, et particulièrement concernant GPT4-o. Cela signifie que dans 80% des cas, avec le pièges le plus élaboré, GPT-4-o parvient à “raisonner” correctement.
Au moment où j’écris ces lignes, l’IA est un outil puissant mais qui a ses biais et limites qu’il est bon de connaitre, et de rester lucide quant à ces capacités.