Depuis que l’IA générative est arrivée sur le devant de la scène, cette technologie se retrouve régulièrement sous le feu des critiques par rapport aux nombreuses questions qu’elle soulève en termes de droit d’auteur et de propriété intellectuelle. Pour entraîner ces modèles, les entreprises qui les alimentent ont souvent tendance à collecter des montagnes de contenu un peu partout sur Internet, sans forcément s’embarrasser de leur provenance ou d’un éventuel copyright.
C’est évidemment très problématique pour les créateurs. Le plus souvent, ils sont totalement impuissants face à ce pillage, et n’ont aucun moyen d’empêcher leurs créations d’être ingurgitées par des modèles IA sans la moindre contrepartie. Mais cette dynamique nauséabonde pose aussi un autre problème, plus discret, pour ceux qui souhaitent utiliser cette technologie à fort potentiel dans le cadre de leur activité professionnelle.
Prenons l’exemple d’une petite agence créative qui souhaiterait utiliser l’IA générative pour produire des visuels intéressants très rapidement. Si le modèle a été entraîné à partir d’une montagne de photos glanées sur le web sans précaution, les images produites pourraient contenir des ressemblances troublantes avec les produits d’autres marques, et donc exposer l’entreprise à des poursuites judiciaires potentiellement catastrophiques.
Pour éviter ce genre de problème, la seule solution est d’entraîner un modèle à partir d’un ensemble d’images triées sur le volet. Mais en pratique, c’est très souvent impossible pour des raisons avant tout économiques : à moins d’ignorer sciemment le droit d’auteur, il faudrait débourser des sommes astronomiques afin d’acquérir les droits de tous ces contenus.
C’est là qu’interviennent Getty Images et sa filiale iStockphoto, qui gèrent une immense banque de plusieurs centaines de millions d’images utilisées par les médias et les créateurs du monde entier. Quand l’IA générative a commencé à se démocratiser et que de nombreuses organisations ont commencé à proposer des services de ce genre, l’entreprise a vite réalisé que cette ressource était un atout colossal. Elle a donc décidé de concevoir son propre modèle, qui vient d’ailleurs de bénéficier d’une mise à jour conséquente.
Des performances plutôt convaincantes…
Au niveau technique, la nouvelle version du système est basée sur l’architecture du modèle Edify d’NVIDIA. Elle bénéficie donc d’un gain de vitesse et de qualité significatif, avec des vitesses de génération au-dessus de la moyenne (un peu moins de 10 secondes pour quatre images) et d’un nouveau système de génération et d’upscaling 4K qui permet de produire des images convaincantes en haute résolution.
Le nouveau modèle supporte des prompts assez longs (jusqu’à 250 caractères), mais selon l’entreprise, il se distingue aussi par sa sensibilité en termes d’alignement. Il est spécifiquement conçu pour tenir compte de chaque terme de la requête textuelle, afin d’offrir un maximum de contrôle à l’utilisateur. La courte démonstration dont nous avons pu bénéficier ne nous a pas permis de parvenir à une conclusion définitive à ce niveau, mais les images produites nous ont semblé très cohérentes avec les requêtes. C’est un avantage significatif par rapport à certains autres modèles pourtant très performants comme MidjourneyAI, qui a la fâcheuse habitude d’ignorer certains termes importants des prompts.
En revanche, par rapport à ce dernier, le modèle de Getty nous a semblé en retrait en termes de flexibilité. Il ne prend pas en charge les paramètres qui offrent un haut degré de contrôle aux utilisateurs de Midjourney (format, randomisation, références stylistiques…). A la place, il faut se contenter de quelques paramètres préprogrammés.
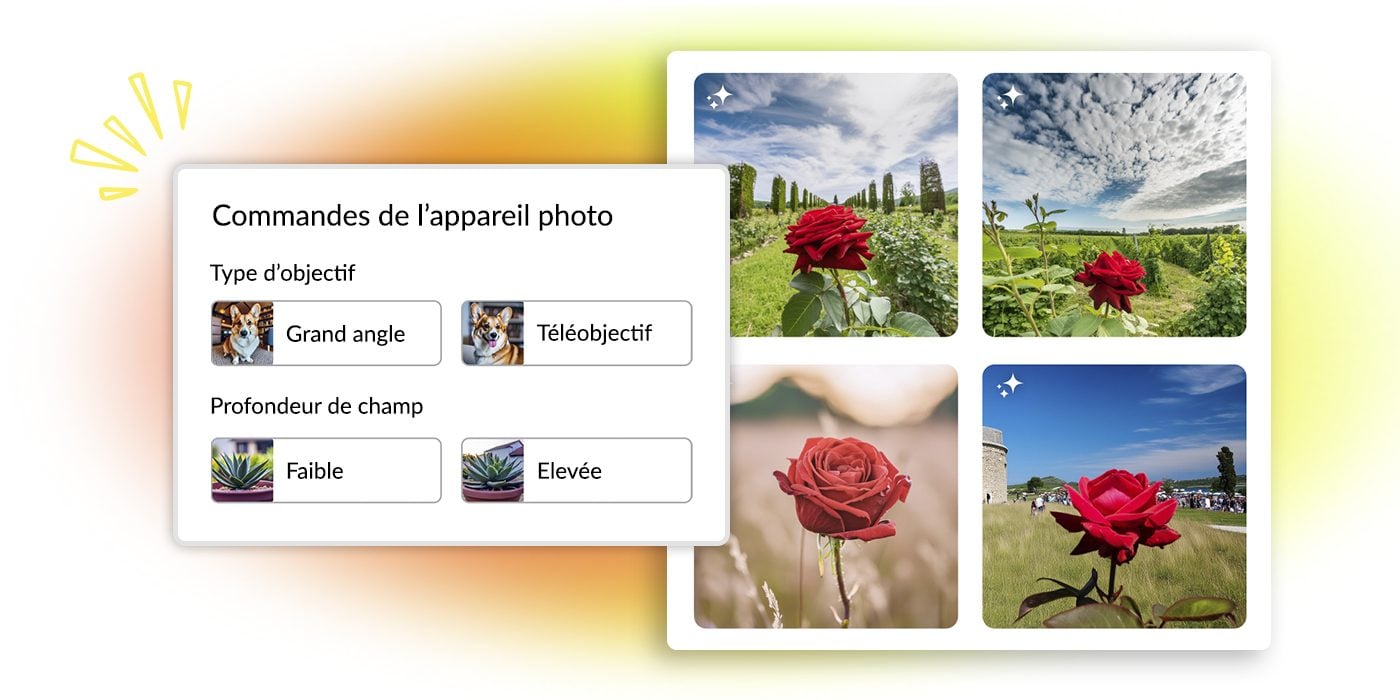
Cela a l’avantage de rendre le système plus intuitif, mais cela pourrait aussi limiter sa polyvalence globale ; pour arriver au résultat souhaité, il faut impérativement créer un prompt très précis et descriptif. Cette lacune est toutefois partiellement compensée par une fonction de retouche qui permet de re-générer un élément précis de l’image à l’aide d’un prompt supplémentaire.
Mais surtout de vraies garanties pour les professionnels
Mais ce qui permet vraiment à ce modèle de se distinguer par rapport à sa concurrence, c’est le matériel qui a servi à l’entraîner. Selon Grant Farhall, Chief Product Officer de Getty Images, l’entreprise utilise uniquement sa propre banque d’images ; aucun contenu n’a été collecté par un bot sur Internet, même parmi les images sous licence CC et celles du domaine public. En outre, toute la base de données éditoriale de l’entreprise (celle qui rassemble des photos d’événements ou de personnalités célèbres pour illustrer des articles de presse) a été exclue.
Le premier objectif de cette démarche, c’est d’empêcher le modèle d’ingurgiter des images de personnes bien identifiables. Par conséquent, il est techniquement incapable de produire un deepfake d’un acteur, d’un responsable politique, et ainsi de suite. En parallèle, cela permet aussi d’éviter que du contenu couvert par le droit d’auteur ne s’infiltre dans les données d’entraînement. En somme, il est impossible de générer une image de Taylor Swift, de Bob l’Éponge ou d’une chaussure de marque, par exemple ; le modèle n’a tout simplement pas la moindre idée de ce à quoi ces termes font référence. Et si l’utilisateur essaye tout de même de le faire, l’interface va le stopper net. Toute référence à une célébrité ou à un produit grand public dans le prompt génère systématiquement un message d’erreur.
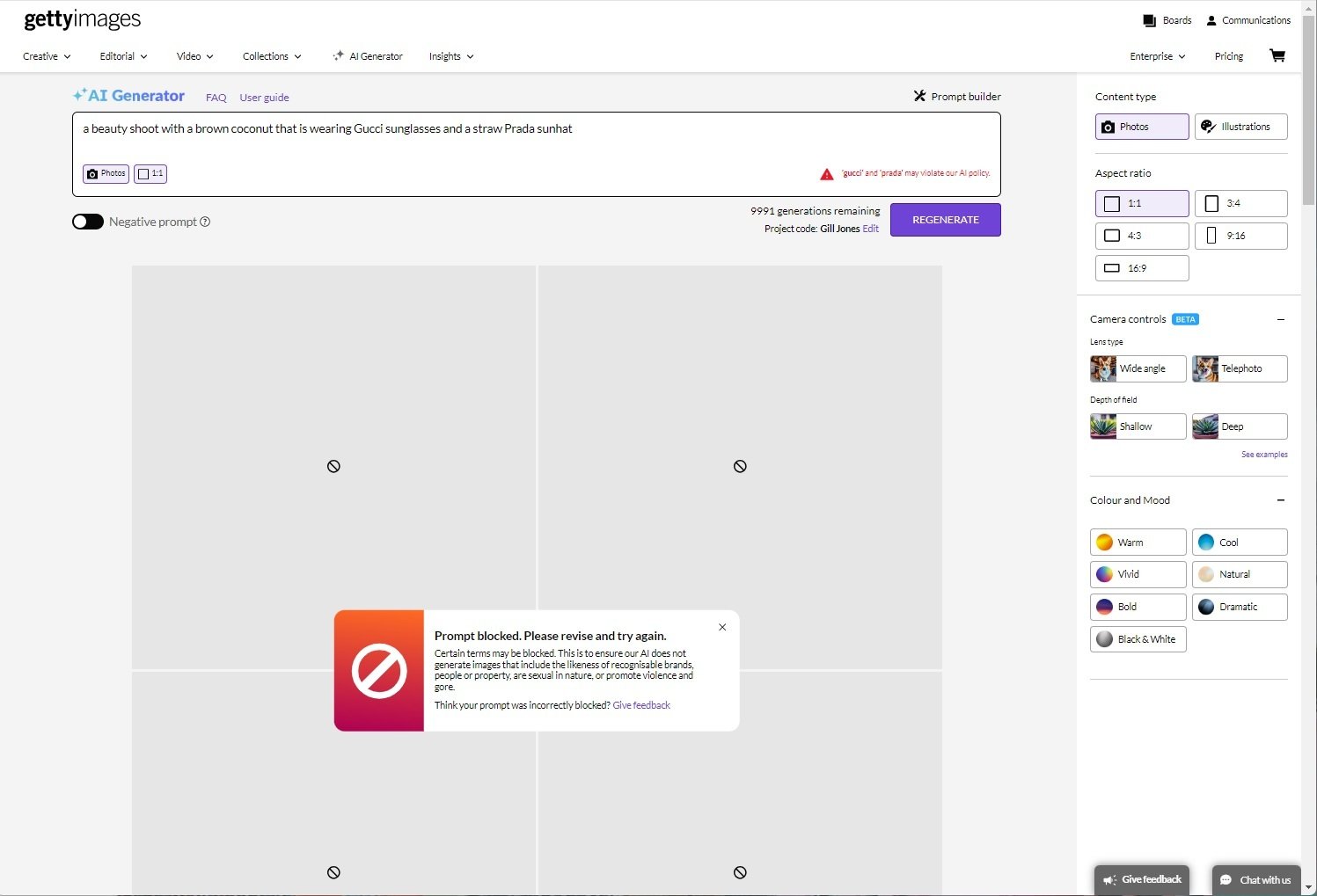
Pour une personne qui souhaite utiliser l’IA pour produire du contenu à vocation commerciale, cette façon de procéder peut être rassurante. On peut le voir comme une sorte de filet de sécurité ; Getty garantit que les images produites par ce modèle ne contiendront aucun élément litigieux qui pourrait déboucher sur une action en justice pour atteinte au droit d’auteur. Les professionnels de la création pourront donc les utiliser sans arrière-pensée dans des publicités, sur des sites web, et ainsi de suite.
Les banques images, futures clés de voûte de l’IA générative ?
En prenant un peu de recul, cette démarche soulève un certain nombre de questions intéressantes sur le futur de l’IA générative dans l’industrie de la création. Aujourd’hui, la législation qui entoure cette technologie et ses implications pour le droit d’auteur est encore très floue. Mais elle va sans doute évoluer et devenir de plus en plus stricte au fil du temps, et il n’est pas exclu que les systèmes qui permettent de scraper automatiquement des tonnes de contenu sur le web pour alimenter des modèles IA finissent par être bannis. Dans ce contexte, certaines entreprises spécialisées dans l’IA générative pourraient se retrouver dans une impasse, car il sera beaucoup plus compliqué de trouver assez de matériel pour entraîner un modèle performant.
Le cas échéant, elles devront sans doute faire appel à d’autres services qui se spécialisent dans la compilation de vastes ensembles de données spécifiquement pour l’entraînement d’IA. Plusieurs entreprises se sont déjà lancées dans cette nouvelle activité à fort potentiel commercial… mais elles ont tendance à profiter du vide juridique pour se livrer à des pratiques pour le moins discutables. On peut notamment citer EuletherAI, l’entreprise à but non lucratif qui gère le projet The Pile. Il s’agit d’un vaste jeu de données contenant du contenu libre comme des articles Wikipédia… mais aussi du matériel sous copyright comme des transcriptions textuelles de vidéos YouTube. Et des entreprises de très gros calibre comme Nvidia ou Apple n’ont pas hésité à piocher dans cette ressource pour alimenter leurs propres modèles, en se réfugiant derrière le fait qu’elles n’avaient pas collecté ce contenu elles-mêmes pour se dédouaner de toute atteinte au droit d’auteur.
Si des lois plus strictes finissent par émerger, les fournisseurs de données qui procèdent de cette manière seront probablement contraints de mettre la clé sous la porte… et c’est là que les entreprises qui gèrent d’énormes banques d’images pourraient avoir une vraie carte à jouer.
En plus de fournir des images brutes aux créateurs et à la presse, Getty Images, mais aussi Shutterstock, Adobe Stock ou encore Alamy, pour ne citer qu’eux, pourraient devenir des maillons incontournables dans la chaîne logistique de l’IA générative. Ce genre de service pourrait vite devenir extrêmement rémunérateur ; grâce à leurs banques d’images déjà colossales, ces entreprises disposent d’une avance énorme sur d’éventuels concurrents qui pourraient tenter de se lancer dans cette activité.
Évidemment, il ne s’agit que de suppositions un brin hasardeuses pour le moment. Mais il sera intéressant de voir comment l’écosystème commercial encore balbutiant qui est en train de se construire autour de l’IA générative va évoluer, et quel sera l’impact pour toutes les entreprises qui misent sur cette technologie.
🟣 Pour ne manquer aucune news sur le Journal du Geek, abonnez-vous sur Google Actualités et sur notre WhatsApp. Et si vous nous adorez, on a une newsletter tous les matins.