
En avril dernier, Meta avait annoncé travailler sur un projet assez excitant : un grand modèle de langage entièrement “open source”, mais néanmoins capable de rivaliser avec les leaders du secteur. Le fruit de ce travail, Llama 3.1, vient d’être présenté officiellement dans un communiqué de l’entreprise.
Cette nomenclature est un brin trompeuse, car elle suggère qu’il ne s’agit que d’une évolution mineure du Llama 3 qui est sorti il y a quelques mois. Mais c’est tout le contraire : il est nettement plus complexe. En particulier, le nombre de paramètres (l’ensemble des poids et des biais, des valeurs numériques qui définissent l’importance des liens entre les différents neurones virtuels du réseau) a explosé : il passe de 140 milliards pour la version 3.0 à 405 milliards pour la version 3.1.
Un vrai rival pour GPT-4
Certes, c’est encore relativement loin de GPT-4, qui compte un total de 1760 milliards de paramètres (ou, plus rigoureusement, 8 x 220 milliards, puisque ce modèle est construit autour d’une architecture Mixture-of-Experts qui consiste à faire communiquer plusieurs sous-unités semi-indépendantes). Mais il est de notoriété publique que la taille ne fait pas tout, et Meta soutient que son produit n’a rien à envier à celui d’OpenAI. Apparemment, Llama 3.1 se montre même plus performant que GPT-4o sur certains benchmarks.
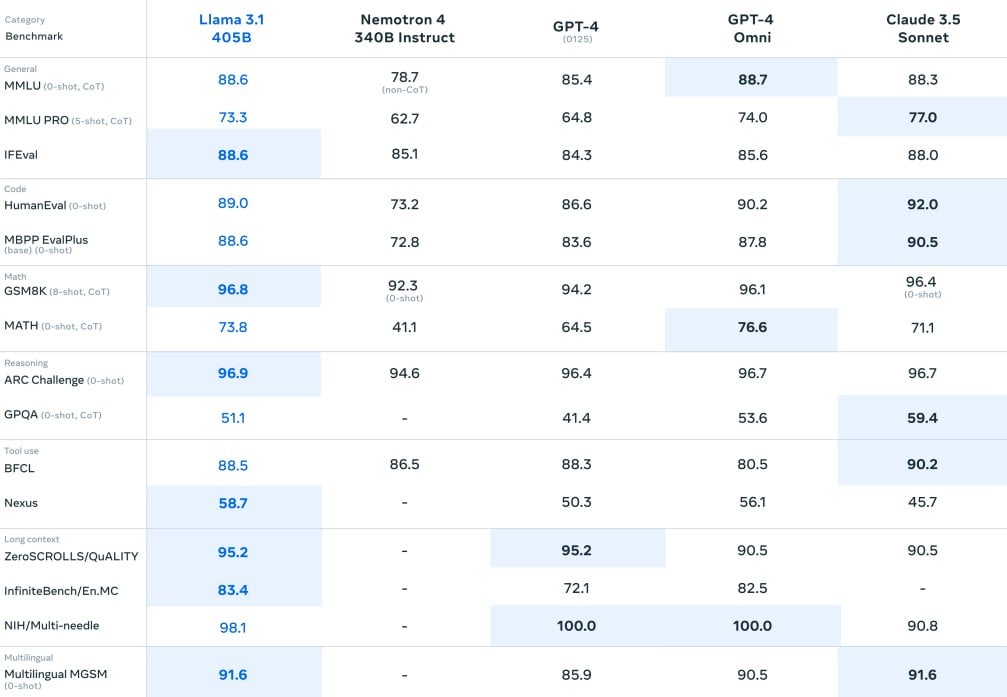
Sur IFEval, un test de performance générale, il score 88,6 points, soit 3 de plus que GPT-4o. Il fait aussi très légèrement mieux sur GSM8K (mathématique) et ARC Challenge (raisonnement), et semble significativement plus à l’aise dans différentes langues (+5 points sur Multilingual MGSM). Les chiffres exacts sont à prendre avec des pincettes, mais dans l’ensemble, ces résultats montrent que Llama 3.1 boxe plus ou moins dans la même catégorie que les leaders de l’industrie.
Il se démarque aussi grâce à sa compatibilité étendue. En effet, pour faciliter son intégration à l’écosystème numérique, Meta a signé des partenariats avec de grands noms comme Amazon Web Systemsn, Nvidia, Microsoft, IBM ou encore Google Cloud.
Un modèle “open source”, vraiment … ?
L’entreprise reste cependant très discrète par rapport aux données qui ont servi à entraîner ce modèle; elle se contente de préciser qu’elle a utilisé des données synthétiques, c’est-à-dire générées ou étiquetées par d’autres modèles de langage (en l’occurrence Llama 2). Comme toujours, il est pratiquement impossible de savoir si Meta est allée piocher dans du contenu couvert par le droit d’auteur pour alimenter sa création. C’est un point très important, car cette façon de procéder va totalement à l’encontre d’une des principales revendications de Meta.
En effet, Meta répète régulièrement que Llama est une famille de modèles “open source”. Il est vrai que l’entreprise donne accès à une portion significative du code et des paramètres de ses modèles. À ce titre, Llama 3.1 est effectivement plus ouvert que les modèles d’OpenAI, qui conserve jalousement les paramètres de ses modèles GPT. Mark Zuckerberg lui-même a d’ailleurs publié un billet sur “l’IA open source”. Vous l’aurez compris, Meta mise beaucoup sur ce label… mais cela ne signifie pas pour autant qu’il est justifié dans ce contexte.
Être plus ouvert qu’un modèle entièrement fermé ne suffit pas à répondre aux critères de l’open source, et force est de constater que Llama ne rentre pas vraiment dans cette catégorie. En plus de refuser la transparence au niveau des données d’entraînement, Meta impose aussi des restrictions significatives à l’usage de son produit. La licence précise explicitement que l’entreprise peut à tout moment couper l’accès au modèle et empêcher les utilisateurs d’exploiter ses productions. Parler d’open source dans ce contexte est donc un gros abus de langage.
L’open source comme caution morale
Et c’est loin d’être une erreur innocente. Meta est forcément conscient que son produit ne répond pas aux critères traditionnels de l’open source. On peut donc interpréter cet usage récurrent du terme comme une volonté de déformer la réalité à des fins de communication, en utilisant ce vocabulaire comme une sorte de caution morale. En substance, Meta fait tout pour marquer sa différence avec les modèles fermés d’OpenAI et consorts pour donner une dimension quasiment philanthropique à ses travaux en IA, quitte à brouiller les pistes et à usurper ce titre pour s’en approprier l’image positive sans respecter les standards qui vont avec.
Forcément, cette démarche irrite passablement les partisans du vrai open source. Depuis la préhistoire du web, des communautés entières de passionnés dévoués s’acharnent à créer des outils formidables que chacun peut utiliser et modifier à sa guise, indépendamment du contexte, avec pour seule motivation de contribuer à l’écosystème numérique. En un sens, la façon de procéder de Meta peut donc être interprétée comme une trahison des idéaux incarnés par ces initiatives, et cela pourrait conduire à une dévaluation regrettable de ce label.
Malgré tout, ceux qui disposent des compétences techniques nécessaires peuvent dès à présent expérimenter avec Llama 3.1 en téléchargeant les différentes versions du modèle sur le site de Meta ou via Hugging Face. Veillez cependant à lire attentivement la licence et la politique d’utilisation pour éviter toute mauvaise surprise.
🟣 Pour ne manquer aucune news sur le Journal du Geek, abonnez-vous sur Google Actualités et sur notre WhatsApp. Et si vous nous adorez, on a une newsletter tous les matins.











Merci pour cet article. Il est en effet important de comprendre ces enjeux et ne pas laisser faire les GAFAM et autres BATX prendre le contrôle totale de ce marché de l’IA. On a vu dernièrement les conséquences possibles avec la panne mondiale CrowdStrike.
Il nous faut des alternatives vraiment Open Source et Européennes.
Aller chercher du côté des données d’entraînement et des limitations à donner à ses usages, il n’y a pas de quoi se bousculer la paillasse pour dénoncer un abus de langage sur l’Open Source. Vous feriez mieux d’interroger directement Yann Le Cun pour vos interrogations plutôt qu’etaler des suppositions un peu fumeuses dans un contexte de radicalisation malsaine.