GPT-4 est déjà capable de produire des extraits de code assez impressionnants, susceptibles de faciliter la vie des développeurs les moins expérimentés où à ceux qui ont soudainement besoin de travailler avec un langage dont ils ne maîtrisent pas la syntaxe. En revanche, il a aussi la fâcheuse habitude de commettre de grosses erreurs susceptibles de rendre les résultats inutilisables.
Pour combler cette lacune, OpenAI a choisi de le faire superviser par… un autre modèle IA dérivé de GPT-4, baptisé CriticGPT.

Une collaboration entre l’humain et la machine
Sa particularité, c’est qu’il ne travaille pas entièrement en autonomie. Il s’intègre dans un processus qu’OpenAI appelle le RLHF, pour Reinforcement Learning from Human Feedback (Apprentissage par renforcement à partir de la rétroaction humaine). L’idée centrale de ce concept, c’est de faire contribuer des humains au processus d’entraînement pour réduire le nombre d’hallucinations — les réponses bancales, incohérentes, ou même factuellement fausses que les modèles IA peuvent débiter avec un aplomb déconcertant.
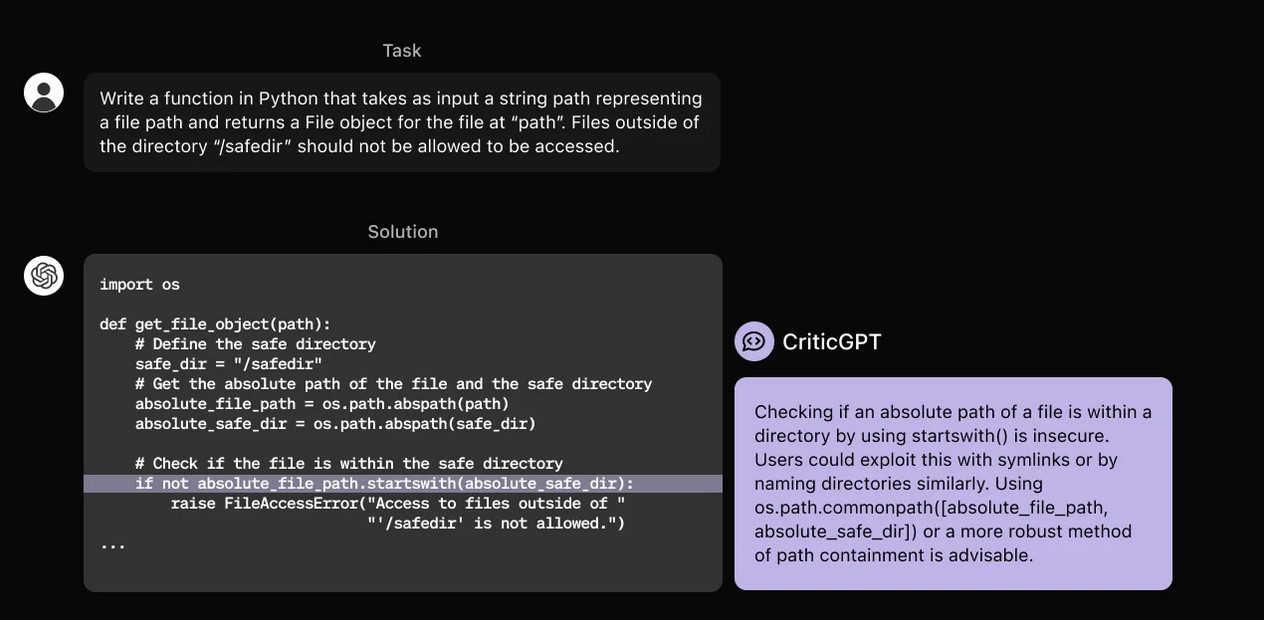
Pour entraîner CriticGPT, les chercheurs lui ont fourni des montagnes de code dans lequel des humains ont intentionnellement introduit des erreurs, puis fourni des exemples de commentaires comme s’ils avaient découvert ces bugs eux-mêmes. Ce coaching a permis au modèle d’apprendre à reconnaître et à corriger une ribambelle de problèmes logiques et syntaxiques divers et variés.
Des résultats déjà intéressants
Les chercheurs ont ensuite fait tester leur système à des développeurs. Les résultats étaient loin d’être parfaits, et ont mis en évidence quelques limites assez importantes. Par exemple, l’équipe d’OpenAI explique que CriticGPT est très performant lorsqu’il s’agit d’identifier une erreur isolée ; en revanche, il a beaucoup plus de mal à résoudre les problèmes qui proviennent des interactions de plusieurs morceaux de code séparés. Un handicap important, sachant que la grande majorité des programmes professionnels sont structurés de cette façon.
Mais au bout du compte, les résultats se sont tout de même avérés plutôt encourageants. En effet, le jury a préféré les critiques formulées par le modèle à celles émanant d’autres humains dans 63 % des cas. Les testeurs ont aussi trouvé que ces recommandations étaient souvent plus détaillées et pertinentes, notamment parce qu’elles se focalisaient sur le problème sans s’éparpiller.
Le remède contre les hallucinations ?
Mais l’application la plus intéressante de ce concept ne réside peut-être pas dans la niche de la programmation par l’IA. En effet, il n’y a pas que dans la génération de code informatique que ChatGPT et consorts ont tendance à halluciner ; cela peut arriver quelle que soit la question posée. OpenAI a donc tenté d’appliquer sa démarche centrée sur les humains dans un contexte plus général.
Plus spécifiquement, ils ont fourni à CriticGPT une partie des données qui ont permis d’entraîner GPT-4. C’est un matériel intéressant, car toutes ces données avaient fait l’objet d’un processus d’étiquetage (on parle parfois d’annotation). C’est une démarche qui consiste à faire valider les données d’entraînement en amont par des humains pour ne pas alimenter l’algorithme avec des âneries qui pourraient nuire à la qualité de ses réponses. En théorie, ce jeu de données aurait dû être exceptionnellement solide. Et pourtant, CriticGPT a identifié des erreurs dans 24 % de ces cas !
Pour OpenAI, cela montre que le système dispose aussi d’un vrai potentiel en dehors de la programmation. Il pourrait aider les annotateurs humains à identifier les données problématiques avant qu’elles ne soient ingurgitées par l’algorithme, ce qui permettrait théoriquement de réduire massivement le nombre d’hallucinations.
Par conséquent, l’entreprise prévoit d’intégrer un modèle critique de ce genre à son processus d’entraînement supervisé. En d’autres termes, un modèle IA va bientôt aider des humains à entraîner d’autres modèles qui pourront à leur tour en critiquer d’autres… et ainsi de suite. In sera intéressant de suivre ces travaux pour voir si cette approche finira par se généraliser, et quelles seront les retombées sur la qualité des modèles.
🟣 Pour ne manquer aucune news sur le Journal du Geek, abonnez-vous sur Google Actualités et sur notre WhatsApp. Et si vous nous adorez, on a une newsletter tous les matins.