
Depuis la sortie de ChatGPT, l’industrie n’a d’yeux que pour les grands modèles de langage, ou LLM (our Large Language Model). De nombreux autres acteurs de l’IA, des titans de la tech comme Meta aux jeunes pousses prometteuses comme Mistral, ont investi ce segment. Mais l’entraînement et l’inférence (les opérations à travers lesquelles un modèle IA déjà entraîné réalise des prédictions à partir de nouvelles données) se paient au prix fort avec des nombres de paramètres très élevés.
De plus en plus de monde commence donc à proposer des modèles de plus petite taille appelés SLM, pour Small Language Models. Ceux-ci sont certes moins performants que les meilleurs LLM, mais potentiellement bien plus rentables. On peut citer Google avec ses modèles Gemma 2B et 7B, Anthropic avec la version Haiku de Claude 3, ou encore Meta avec son Llama 3 8B. Désormais, c’est Microsoft qui retourne dans l’arène avec Phi-3 Mini, le premier d’une famille de trois poids plumes qui devraient sortir sur les prochains mois.
Pas grand, mais vaillant
Dans le domaine du machine learning, le terme de « paramètre » désigne l’ensemble des poids et des biais, des valeurs numériques qui définissent l’importance des liens entre les différents neurones virtuels qui composent le réseau. Phi-3 Mini en utilise 7 milliards, ce qui en fait un véritable poids plume. Pour référence, GPT-4 dispose d’un total de 1760 milliards de paramètres répartis dans un ensemble de 8 sous-modèles.
En règle générale, il s’agit d’un critère important pour les performances d’un modèle IA. Intuitivement, on pourrait donc s’attendre à ce que Phi-3 soit extrêmement limité en termes de performances. Mais en pratique, l’écart avec les fers de lance de cette industrie n’est apparemment pas si important que ça. Microsoft affirme que son petit poucet propose des réponses équivalentes à celles d’autres modèles 10 fois plus lourds. Eric Boyd, le vice-président de la branche IA d’Azure (la division cloud de l’entreprise), a même affirmé à The Verge qu’il était à peu près aussi performant que GPT-3.5. Une revendication pas anodine, sachant que ce dernier était encore le mètre étalon de l’industrie il y a un peu plus d’un an.
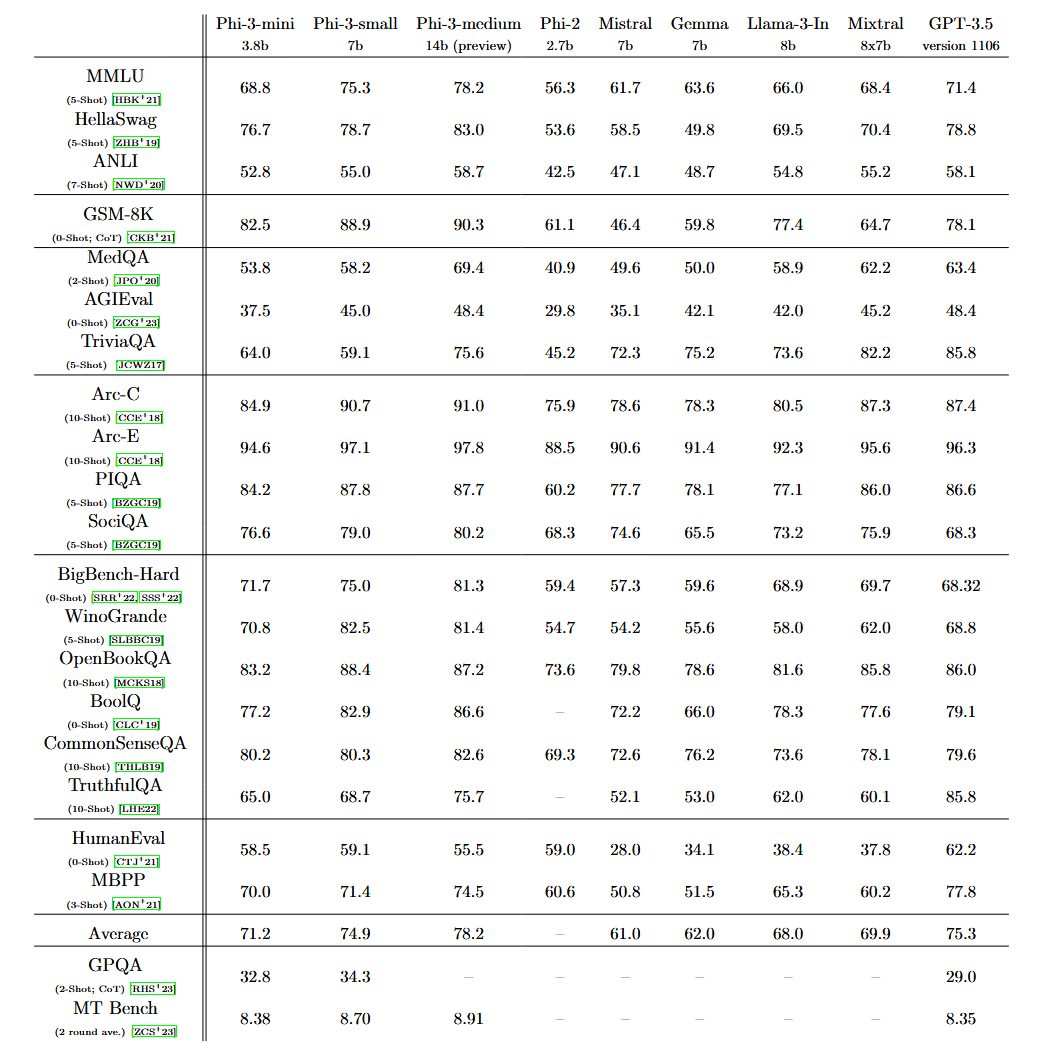
Une nouvelle méthode d’entraînement basée sur la qualité
Pour y parvenir, Microsoft a mis au point un système d’entraînement original inspiré par les enfants. Les LLM sont généralement entraînés sur la base d’une montagne de contenus divers et variés glanés aux quatre coins d’Internet. Les troupes de Microsoft ont misé sur une autre approche qui consiste à lui fournir un ensemble de données beaucoup plus restreint, mais en mettant l’accent sur la qualité.
Microsoft est parti d’un ensemble de 3000 mots très courants, et surtout assez simples pour être compréhensibles par un enfant de 4 ans. À partir de là, les chercheurs ont demandé à un LLM non spécifié (probablement GPT-4, connaissant les liens qui unissent le titan du software et OpenAI) de créer des histoires pour enfant en piochant dans ce dictionnaire soigneusement calibré. Le processus a été répété plusieurs millions de fois pour générer un ensemble de millions de petites histoires baptisé « TinyStories ».
Ce corpus a été utilisé pour entraîner une première version de Phi-3. Et contre toute attente, lorsque les ingénieurs lui ont demandé de créer ses propres histoires, il a réussi à le faire de manière très cohérente avec une grammaire parfaite. À partir de là, ils sont passés à la vitesse supérieure en sélectionnant méticuleusement des « données publiques filtrées sur la base de leur valeur pédagogique et de leur qualité ».
Là encore, l’équipe s’est focalisée sur la qualité du contenu plutôt que sur la quantité. L’objectif, c’était de fournir uniquement du matériel très clair et explicite au modèle pour maximiser l’efficacité du processus d’apprentissage, un peu comme un professeur qui décortique un concept difficile pour permettre à son étudiant de se l’approprier. « C’est comme travailler avec un livre scolaire ; en partant de documents de qualité qui expliquent très bien les choses, on facilite énormément l’apprentissage du modèle », explique le communiqué de l’entreprise.
Un nouveau paradigme pour l’IA grand public ?
Il s’agit d’une approche intéressante qui permet d’obtenir de bons résultats malgré le nombre de paramètres assez restreint. De plus, cette philosophie qui privilégie la qualité à la quantité pourrait faire des merveilles sur un modèle de plus grande taille. Malheureusement, cette façon de travailler est fondamentalement incompatible avec les LLM pour le moment. Pour filtrer suffisamment de données pour alimenter ces mastodontes, il faudrait une véritable armée d’humains.
Malgré tout, les géants de l’IA ont tout de même intérêt à s’inspirer de cette façon de faire. Car en ce moment, le nombre de paramètres des LLM explose à chaque génération. Or, cela se répercute fatalement sur la puissance de calcul nécessaire, et par extension sur le prix opérationnel. Ce n’est pas un hasard si OpenAI et Microsoft veulent apparemment construire un supercalculateur à 100 milliards de dollars.
Dans ce contexte, on risque fort d’arriver à une sorte de goulot d’étranglement où les progrès du machine learning seront conditionnés par les progrès du côté hardware, et aussi par la quantité de matériel disponible. Un gros problème, sachant que les chaînes de logistique fonctionnent déjà à flux tendu. Les carnets de commande d’Nvidia, par exemple, sont déjà pleins à craquer, car tous les cadors de cette industrie jouent des coudes pour acheter autant de GPU que possible.
Il sera donc intéressant de voir si certaines entreprises vont tenter de développer d’autres stratégies. On peut par exemple imaginer des modèles IA spécialisés dans le filtrage et la synthèse des données d’entraînement, afin d’augmenter la qualité des agents conversationnels sans faire exploser le nombre de paramètres. A terme, cela permettra peut-être de produire une nouvelle génération de modèles plutôt performants, mais beaucoup moins chers et moins dépendants de la puissance de calcul. Certes, il est encore trop tôt pour signer l’acte de décès des LLM. Mais il conviendra de garder un oeil sur cette tendance qui pourrait se transformer en nouveau paradigme dans un futur relativement proche.
🟣 Pour ne manquer aucune news sur le Journal du Geek, abonnez-vous sur Google Actualités et sur notre WhatsApp. Et si vous nous adorez, on a une newsletter tous les matins.










