
Entre les modèles de langage comme ChatGPT, les générateurs d’images comme Midjourney et toute la panoplie de nouveaux outils basés sur l’IA qui déferlent en ce moment, les amoureux du machine learning ont largement de quoi s’amuser. Mais ce qu’il y a de plus impressionnant avec ces outils, c’est la vitesse à laquelle ils progressent. La plupart d’entre eux avaient encore du mal à proposer des résultats vaguement cohérents il y a tout juste un an. Aujourd’hui, ils génèrent des conversations ou des photos plus vraies que nature. Et ce n’est pas près de s’arrêter.
C’est en tout cas ce qui ressort de la conférence de la firme à l’IEEE Conference on Computer Vision and Pattern Recognition repérée par Übergizmo. La firme travaille sur l’intelligence artificielle depuis belle lurette. En 2019, nous vous parlions déjà de GauGan, un précurseur qui a grandement participé au développement des générateurs d’images modernes.
Cette fois, le géant vert revient sur le devant de la scène avec une nouvelle ambition : démocratiser la génération de vidéos entières. Le leader mondial des GPU a livré de nombreux détails techniques dans un billet publié sur la plateforme Nvidia Research.
De la diapo à la vidéo
Il s’agit d’un système assez complexe qui fait intervenir plusieurs modèles IA distincts. Tout commence avec un modèle de diffusion latent (ou LDM, pour Latent Diffusion Model) basé sur Stable Diffusion. Rien de très original jusque-là. C’est simplement un algorithme qui a été entraîné à générer des images à partir d’une simple requête textuelle, ou prompt.
Un second système entre alors dans la danse. Celui-ci est assez différent ; il n’a pas été entraîné à générer des images. À la place, il a décortiqué des milliers d’heures de contenu pour définir des « règles » qui permettent aux images de s’enchaîner de façon fluide et cohérente. Cela peut sembler trivial et abstrait pour un humain ; pas besoin d’être un expert pour différencier une vraie vidéo d’un diaporama. Mais c’est plus compliqué pour un ordinateur dénué de notre intuition.
Ensuite, le modèle applique ces motifs aux images générées par le premier modèle. Grâce à l’expérience acquise en analysant ces vidéos, l’algorithme commence par estimer quelles portions de l’image sont susceptibles de changer.
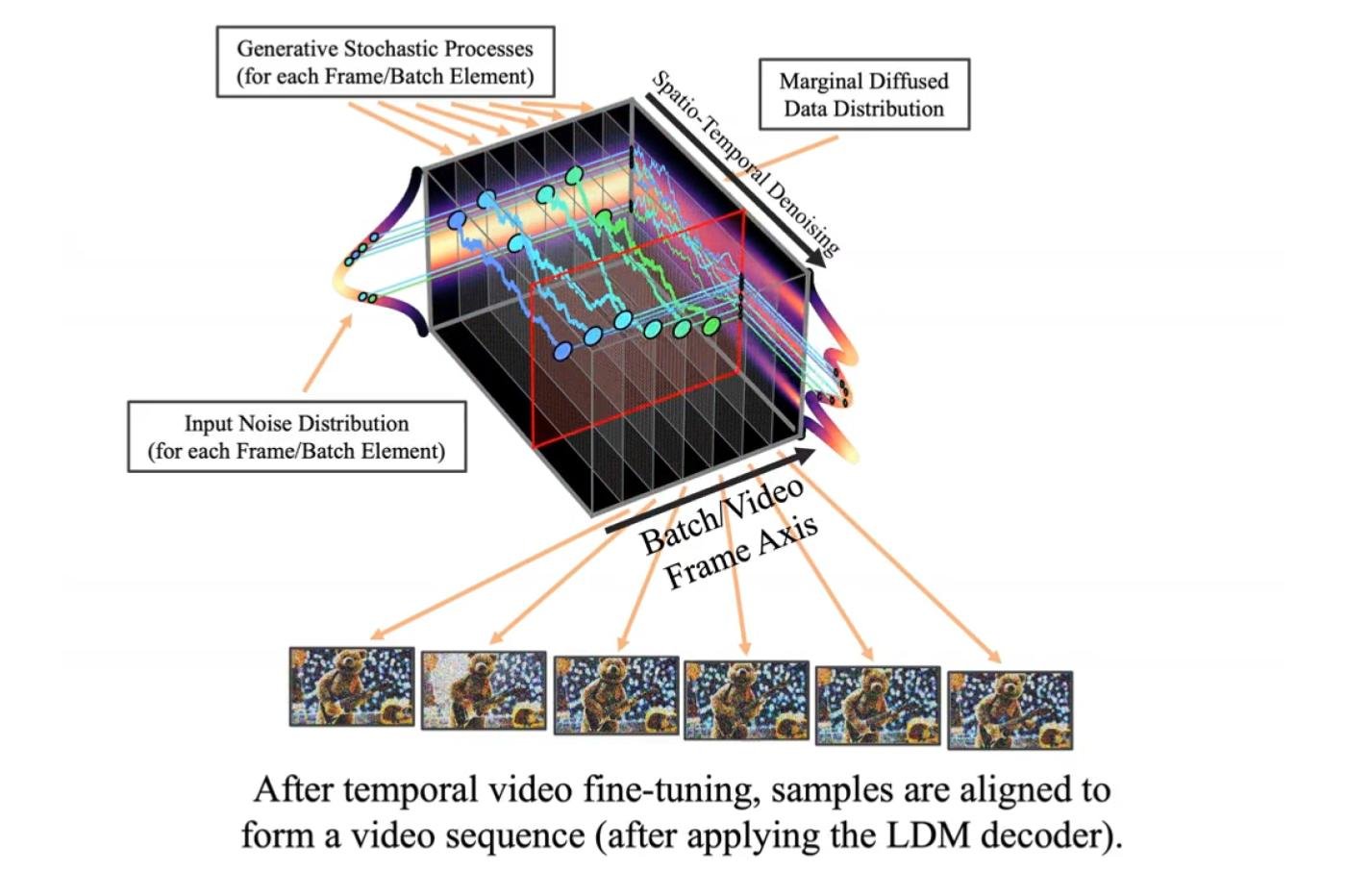
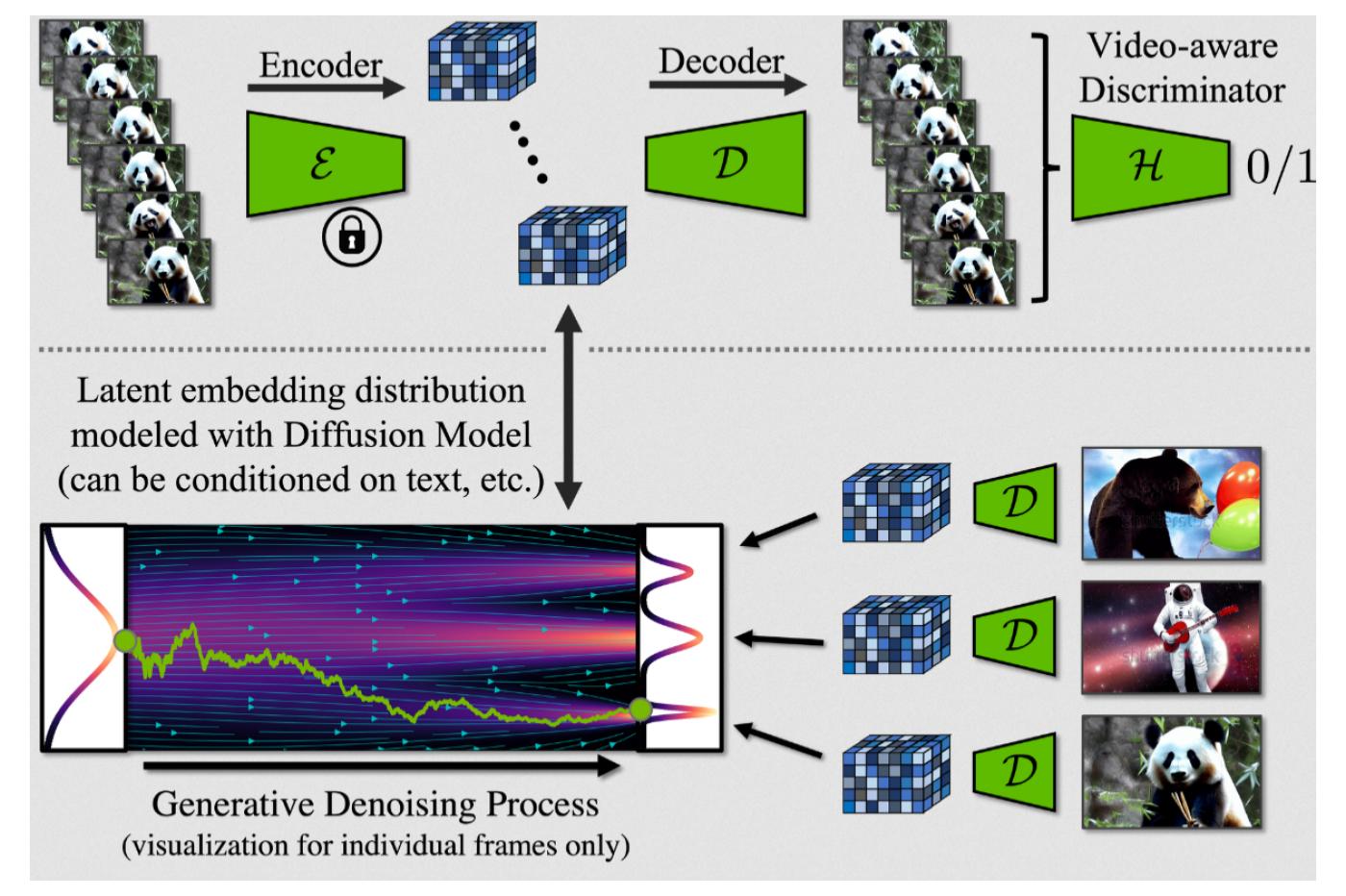
À partir de là, il réalise ce qu’on appelle une interpolation. Très vulgairement, cela consiste à « remplir les trous » d’un ensemble de données en calculant la valeur d’un paramètre entre deux points donnés. Vous avez peut-être utilisé ce concept sans même le savoir en cours de mathématiques. Lorsque votre professeur vous a demandé de tracer la courbe d’une fonction à partir de quelques points isolés, vous avez instinctivement réalisé plusieurs interpolations.
Dans le contexte de la génération d’image, ce ne sont plus de simples valeurs numériques qu’on cherche à interpoler, mais la couleur des pixels. Cela permet de faire en sorte que la vidéo générée reste cohérente d’une image à l’autre.
Des résultats déjà convaincants
Nvidia a d’abord testé ce système en utilisant les images collectées par des dashcam. Leur LDM a été capable de générer plusieurs minutes d’images cohérentes avec une résolution de 512 x 1024 pixels — une combinaison jamais vue jusqu’à présent.
🤯This is bonkers! Nothing in this video is real, it's all #AI generated by NVIDIA team using their Video LDMs!
This is a Specific Driving Scenario Simulation by training a bounding box-conditioned image-only LDM
And more in thread 🧵 pic.twitter.com/sQIPLE6x7H
— Min Choi (@minchoi) April 20, 2023
Dans son papier, la firme présente aussi d’autres exemples plus courts, mais avec une résolution encore plus importante. On y découvre par exemple un extrait d’un ours en peluche en train de jouer de la guitare en 1280 x 2048 pixels.
1/ Nvidia releases Video Latent Diffusion Models
Let’s start with the basics.
A Latent Diffusion Model (LDM) is a way of creating realistic images or videos using AI.
It learns patterns from other images without needing a super-powerful computer. pic.twitter.com/BIpxt9Ory2
— Alex Banks (@thealexbanks) April 20, 2023
Le résultat est nettement moins cohérent. Les frettes ont par exemple tendance à se promener sur le manche de l’instrument. Mais on observe que dans les grandes lignes, le modèle a bien compris ce qu’on attendait de lui. L’approche fonctionne, c’est indéniable. Il ne reste plus qu’à affiner la pondération des modèles IA pour rendre la vidéo encore plus convaincante.
Et dans l’ensemble, le constat est à peu près le même sur les autres exemples produits par Nvidia. La gestion de la lumière, en particulier, est assez impressionnante. La firme a mis à disposition une galerie avec ses productions les plus intéressantes à cette adresse.
Attention, cependant. Ne cliquez sur ce lien que si vous disposez d’une carte graphique puissante et d’une bonne dose de mémoire vive. La page est truffée de vidéos en haute définition qui tournent en même temps. Les machines moins performantes pourraient planter assez rapidement.
Une grande convergence de l’IA générative
Ce qui est particulièrement intéressant avec ces travaux, c’est que l’on assiste en direct à l’émergence d’un tout nouvel écosystème multimédia basé sur différents modèles IA complémentaires. Un exemple parmi d’autres : on peut imaginer qu’il sera bientôt possible de synthétiser un film entier grâce au machine learning.
On pourrait générer un scénario grâce à un LLM comme GPT-4, puis des descriptions des différentes scènes. Ces descriptions seraient ensuite utilisées comme prompts pour générer des images grâce à un outil comme Midjourney. Il ne resterait plus qu’à réaliser une grande série d’interpolations. Ajoutez encore des dialogues générés grâce à un système text-to-speech, et pouf ! Vous obtenez un véritable long-métrage entièrement synthétisé avec des outils IA.
Évidemment, ce n’est pas encore possible à l’heure actuelle. Mais vu la vitesse à laquelle ces technologies progressent, ce n’est probablement qu’une question de temps avant que ces concepts ne deviennent réalité, alors qu’ils relevaient encore de la science-fiction pure et dure il y a quelques années.
Pour le moment, il est encore difficile d’appréhender l’ampleur de ces immenses bouleversements technologiques. Tout ne sera pas rose, c’est certain. La convergence de ces technologies va forcément apporter quelques révolutions objectivement bénéfiques. Mais elle générera aussi de nouveaux débats sur la nature de l’art, la désinformation, et ainsi de suite. Il convient donc de s’y préparer, car une chose est sûre : la machine est déjà lancée, pour le meilleur et pour le pire.
🟣 Pour ne manquer aucune news sur le Journal du Geek, abonnez-vous sur Google Actualités et sur notre WhatsApp. Et si vous nous adorez, on a une newsletter tous les matins.









C’est la fin de l’information. Il n’y aura plus que du bruit.
C’est déjà difficile de faire entendre raison à certains alors qu’ils ne se basent que du texte et quelques photos sorties de leur contexte. On se dirige vers pire.
Il va être urgent d’acheter du barbelé électrifié pour mettre autour du jardin…