L’une des grandes évolutions de GPT-4, la prochaine version du modèle de langage d’OpenAI qui arrive très bientôt, c’est que la firme a mis l’accent sur la multimodalité. En substance, cela signifie que le programme sera capable d’extraire des informations concrètes de différents types de média. L’algorithme pourra désormais travailler avec du son, des images et des vidéos, et plus seulement avec du texte (voir notre article pour plus de détails).
Ses réponses, en revanche, seront toujours proposées au format textuel. Mais Microsoft, l’un des principaux actionnaires de la firme californienne, a choisi d’explorer une autre piste. Dans un papier académique repéré par Tom’s Guide, le géant du numérique vient de présenter Visual ChatGPT. Comme son nom l’indique, il s’agit d’une déclinaison du chatbot qui communique à l’aide d’images.
À première vue, on pourrait croire à un simple doublon de DALL-E, le système de génération d’images d’OpenAI qui avait stupéfié tout l’Internet avant que le chatbot ne mette la barre encore plus haut. Mais Visual ChatGPT va plus loin.
Un chatbot qui exploite la génération d’images
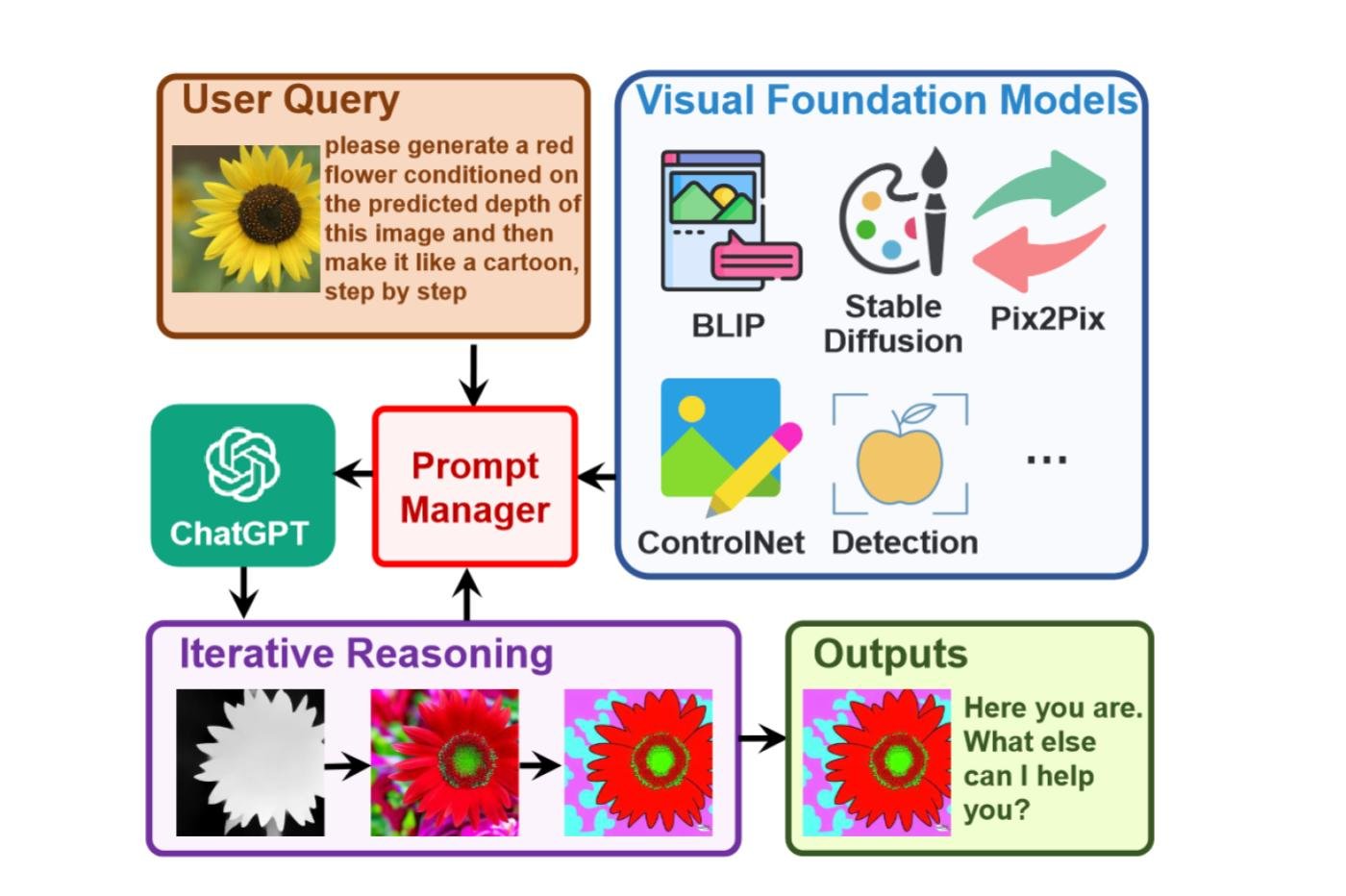
La grande majorité des générateurs d’images reposent sur ce qu’on appelle des Visual Foundation Models (ou modèle visuel de fondation). On peut par exemple citer Visual Transformers ou Stable Diffusion. Ce VFM, c’est un peu la fondation de l’algorithme. Très vulgairement, c’est lui qui se charge de “traduire” les données brutes issues d’un système de vision par ordinateur pour qu’elles puissent être utilisées par d’autres programmes basés sur l’IA, et vice versa. Ces VFM peuvent se suffire à eux-mêmes, mais ils servent généralement de base à des programmes plus complexes.
Le souci, c’est que selon les chercheurs, ce sont des programmes ultraspécialisés qui ne conviennent qu’à une tâche bien précise. Microsoft a donc opté pour une approche assez particulière. Les auteurs de ces travaux ont créé un gestionnaire de requêtes (« prompt manager ») pour combler le fossé qui sépare le chatbot assez généraliste de ces programmes spécialisés. Ils ont donc pu intégrer une pléthore de VFM différents à Visual ChatGPT.
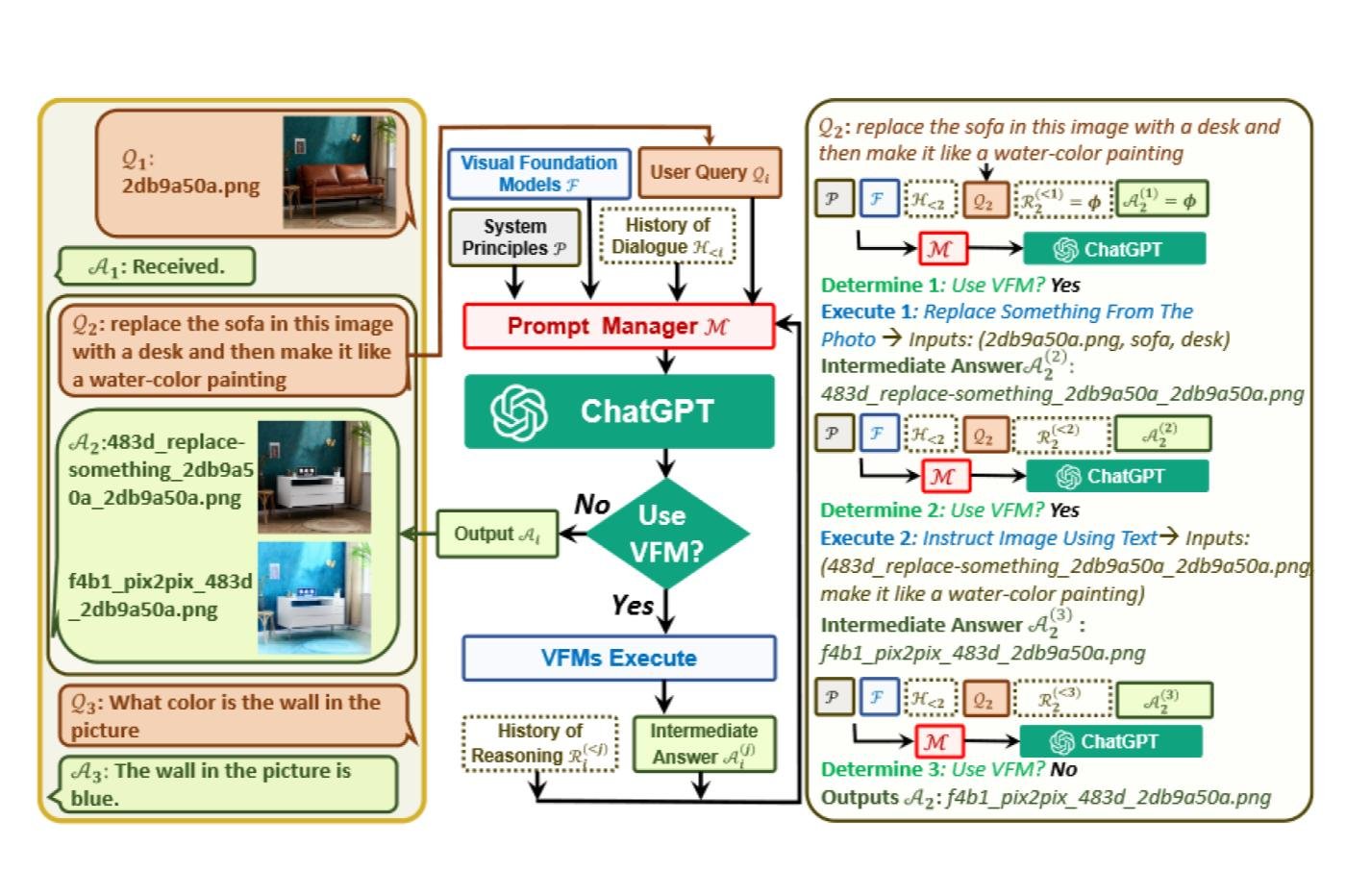
Ce dernier peut ainsi mettre différents modèles génératifs à contribution, puis analyser le résultat au fil des itérations. À chaque étape, l’utilisateur peut réclamer des modifications précises. Il suffit pour cela de proposer une image ou une nouvelle indication textuelle. Le programme va alors en tenir compte afin de produire une image qui répond parfaitement aux attentes. C’est une variante de l’approche Chain of Thought très prometteuse que Microsoft a déjà exploré avec son modèle Kosmos-1 (voir notre article).
Une explosion du nombre de possibilités
Le plus impressionnant, c’est la capacité de l’algorithme à extraire des informations très précises d’une image. Dans cet exemple, il a réussi à générer une carte de profondeur (depth map) d’une image, c’est à dire une texture qui définit la distance de chaque pixel par rapport à une caméra imaginaire.

D’autres exemples présentent d’autres cartes de ce genre, comme des cartes de bordure (edge maps). C’est typiquement le genre de ressource qui peut se révéler très utile pour composer de nouvelles images cohérentes à partir du fichier original… et même davantage.
En effet, les artistes auront probablement flairé le potentiel virtuellement infini de ce genre de fonctionnalité dans le cadre de la modélisation 3D. Car si l’algorithme peut produire ce genre de cartes, cela signifie qu’il est capable d’extrapoler la topologie d’un objet à partir d’une représentation en 2D. A moyen terme, on peut donc s’attendre à voir émerger un tas de nouveaux outils basés sur l’IA qui permettront de générer de fabuleux modèles 3D sur mesure, avec un degré de contrôle hallucinant. Et le tout sans s’embarrasser des corvées techniques chronophages comme la cartographie UV. Quel paradis !
Un avant-goût des futurs chatbots multimodaux
Pour l’instant, le système est encore loin d’être parfait. Les auteurs ont encore remarqué de nombreuses incohérences. Ils estiment qu’elles sont liées à la grande diversité des requêtes. En effet, ces dernières qui ne sont pas interprétées de la même façon par les différents VFM. Mais il s’agit tout de même d’un excellent exemple du genre de résultat auquel on peut s’attendre avec les futurs chatbots multimodaux, à commencer par GPT-4.
Cette nouvelle version du LLM devrait être déployée officiellement d’ici quelques semaines. Et si l’on se base sur les travaux récents de Microsoft, mais aussi d’autres entités comme Amazon (voir nos articles ici et là), il y a fort à parier que ces modèles multimodaux seront au cœur d’une nouvelle avancée spectaculaire dans le monde de l’IA générative. Rendez-vous la semaine prochaine pour vérifier si le nouveau ChatGPT sera aussi impressionnant que prévu !
Le texte de ces travaux est disponible ici, et le code source est accessible depuis ce repository GitHub.
🟣 Pour ne manquer aucune news sur le Journal du Geek, abonnez-vous sur Google Actualités et sur notre WhatsApp. Et si vous nous adorez, on a une newsletter tous les matins.