
Chaque année, la Nvidia GPU Technology Conference constitue l’un des temps forts incontournables du calendrier des professionnels de l’ IA et autres disciplines liées à l’informatique haute performance (HPC). Et 2022 ne fera pas exception; la firme a dévoilé hier soir les premiers produits de sa nouvelle architecture Hopper. Au menu : une toute nouvelle puce GPU H100 et une “superpuce” CPU qui donnent déjà des sueurs froides aux professionnels concernés.
Lors de sa conférence, l’écurie verte a rappelé à tout le monde pourquoi elle figure dans le top 10 des entreprises les plus valorisées au monde. En effet, Nvidia a parfaitement négocié le virage de l’IA sur cette dernière décennie en identifiant très tôt le potentiel de cette technologie; elle a donc pu proposer d’excellents produits qui ont assurément participé à son développement.
Mais le machine learning continue de progresser. La firme explique que les méga-réseaux neuronaux, comme ceux qui ont permis de produire la base de données révolutionnaire d’Alpha Fold, deviennent immensément complexes. Dans le cas de GPT-2, l’IA dédiée au langage de Google, le réseau comportait environ 1,5 milliard de paramètres distincts en 2019; l’année dernière, avec la version GPT-3, ce chiffre a dépassé les 1,5 billion (millions de millions) !
Le problème, c’est que plus cette complexité augmente, plus les modèles deviennent longs à entraîner. À moins d’une véritable révolution algorithmique, il n’y a donc pas de secret : il faut mettre les bouchées doubles du côté du hardware. Et ça, Nvidia l’a bien compris, car c’est précisément l’objectif numéro un de cette architecture Hopper.
En effet, la firme affirme que cette architecture est spécialement conçue pour accélérer l’entraînement de réseaux dits “Transformers”. Rien à voir avec les films de Michael Bay ; très sommairement, ce terme désigne simplement une technologie de machine learning sur laquelle se basent certains des systèmes IA les plus complexes au monde, comme GPT-3.
Nvidia H100 : un monstre de GPU optimisé pour l’IA
D’après Nvidia, cette nouvelle architecture Hopper permettrait aux nouveaux GPU H100 d’entraîner ces modèles jusqu’à… six fois plus vite. De plus, H100 sera compatible avec la toute nouvelle version du NVLink, le successeur du SLI. Il sera donc possible de monter jusqu’à 256 GPU H100 en série ! Tout simplement ébouriffant, sachant que cette puce est déjà un petit monstre en elle-même.
En effet, du haut de ses 80 milliards de transistors, H100 est le tout premier GPU au monde à prendre en charge la norme PCIe Gen 5. En soi, il s’agit déjà d’une information importante puisque la bande passante de ce nouveau standard a été plus ou moins doublée par rapport à la norme PCIe 4. De plus, elle utilisera aussi l’interface HBM3, et atteindra donc une bande passante mémoire d’environ 3 To/s.
Tous ces éléments mis bout à bout, le GPU H100 serait environ trois fois plus rapide que l’A100 pour les opérations de base. Impressionnant sachant que ce dernier est un monstre que l’on retrouve aujourd’hui dans des tas de supercalculateurs de pointe. De plus, sur des modèles Transformers géants comme GPT-3, les performances seraient 9 fois supérieures. Un véritable torrent de données qui’il va bien falloir gérer.


Grace : une double “superpuce” qui s’annonce ébouriffante
Pour cela, Nvidia a aussi présenté Grâce, sa nouvelle “superpuce CPU”. Et c’est un objet assez fascinant pour les amateurs de hardware. En substance, il s’agit de deux CPUS distincts, mais reliés par une technologie analogue au NVLink GPU; on parle alors de NVLink-C2C.
Cela vous rappelle quelque chose ? C’est normal : récemment, Apple nous a dévoilé son processeur M1 Ultra qui est, techniquement, un couple de puces M1 Max agglomérées sur un même support. La technique est assez différente, mais force est de constater que cette approche qui consiste à accumuler des puces déjà existantes a le vent en poupe.
Mais Grace boxe dans une tout autre catégorie que la puce d’Apple; cette puce embarque pas moins de 144 cœurs Arm avec une bande passante d’ 1 To/s. En d’autres termes, vous ne retrouverez pas cet engin dans un ordinateur standard. Ici, nous ne parlons pas d’un CPU grand public, mais d’une machine de guerre conçue pour servir dans le cadre de serveurs et de machines HPC “à une échelle gigantesque”.
Grâce pourra servir dans deux cas de figure différents. Il sera compatible avec des serveurs basés sur une architecture 100% CPU; mais il sera aussi capable de piloter une armada de puces H100 dans des machines accélérées par GPU.
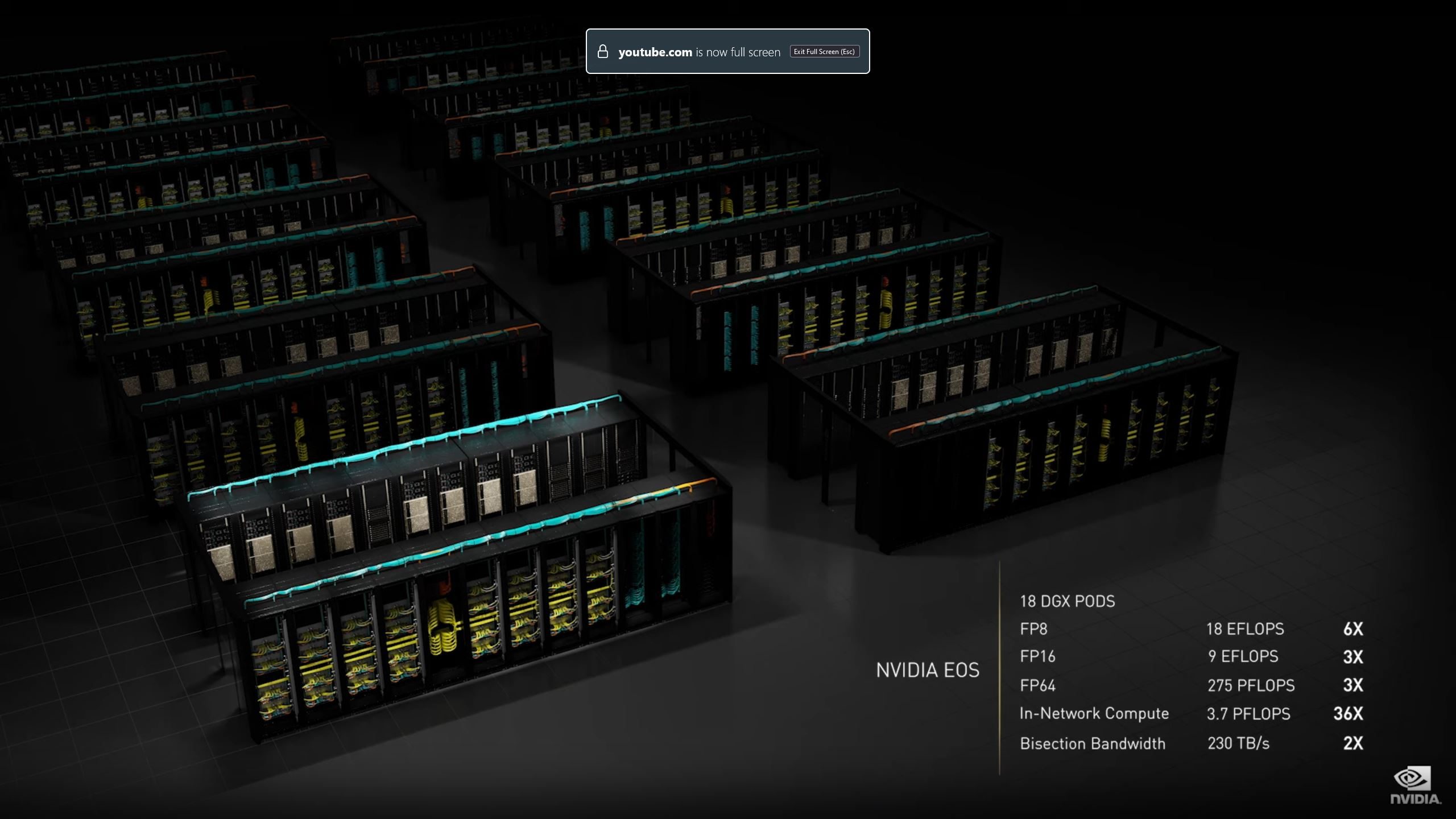
Le futur roi des supercalculateurs IA est en route
Pour mettre tout ce beau matériel à contribution, Nvidia aussi annoncé qu’elle allait construire un nouveau “supercalculateur IA”. Ce sont des machines assez différentes des supercalculateurs traditionnels; comme leur nom l’indique, ils sont optimisés spécifiquement pour les applications liées à l’intelligence artificielle.
Elle affirme qu’une fois terminé, cet engin baptisé Eos sera “le supercalculateur le plus rapide au monde”. Et pour y parvenir, l’écurie verte compte bien mettre sa nouvelle architecture Hopper à contribution.
En effet, l’engin embarquera pas moins de 4600 exemplaires de ce nouveau GPU H100. De quoi oblitérer la fameuse barre symbolique de l’exaflop; une telle machine serait même capable d’offrir 18.4 exaflops de “performance IA”, soit 18,4 milliards de milliards d’opérations chaque seconde. De quoi faire trembler les réseaux neuronaux les plus alambiqués au monde.
Avec tout ce nouveau matériel de pointe à disposition, on peut donc légitimement s’attendre à de nouvelles percées spectaculaires dans le monde de l’intelligence artificielle, et ce dans un futur assez proche.
🟣 Pour ne manquer aucune news sur le Journal du Geek, abonnez-vous sur Google Actualités et sur notre WhatsApp. Et si vous nous adorez, on a une newsletter tous les matins.









